Before we understand LSM, let’s understand the key concepts of SS Tables
SS Tables
- Stands for Sorted String tables
- Used to overcome the challenges posed by log segments with hash indexes i.e. unsorted data and limited support for range queries
- They are data files storing key-value pairs in sorted order.
- Efficient for range queries due to their sorted nature
- Example: Think of an SSTable as a sorted list in a notebook, where you’ve written down names and phone numbers in alphabetical order for quick lookups.
LSM Algorithm
Storage of data
- Also called, Log-Structured Merge Tree Algorithm
- When a write comes in, add it to an in-memory balanced tree data structure (for example, a red-black tree). This in-memory tree is sometimes called a memtable.
- When the memtable gets bigger than some threshold—typically a few megabytes—write it out to disk as an SSTable file. This can be done efficiently because the tree already maintains the key-value pairs sorted by key. The new SSTable file becomes the most recent segment of the database. While the SSTable is being written out to disk, writes can continue to a new memtable instance.
- In order to serve a read request, first try to find the key in the memtable, then in the most recent on-disk segment, then in the next-older segment, etc.
- From time to time, run a merging and compaction process in the background to combine segment files and to discard overwritten or deleted values.
- This scheme works very well. It only suffers from one problem: if the database crashes, the most recent writes (which are in the memtable but not yet written out to disk) are lost. In order to avoid that problem, we can keep a separate log on disk to which every write is immediately appended, just like in the previous section. That log is not in sorted order, but that doesn’t matter, because its only purpose is to restore the memtable after a crash. Every time the memtable is written out to an SSTable, the corresponding log can be discarded.
Compaction
- Assumption: Each segment is a SSTable i.e. stores data sorted by key. Refer above section on how this can be achieved.
- Assumption: A merged segment file will have each key only once (compaction process).
- Start reading the input files side by side, look at the first key in each file, copy the lowest key (according to the sort order) to the output file, and repeat. This produces a new merged segment file, also sorted by key.
- What if the same key appears in several input segments? Remember that each segment contains all the values written to the database during some period of time. This means that all the values in one input segment must be more recent than all the values in the other segment (assuming that we always merge adjacent segments). When multiple segments contain the same key, we can keep the value from the most recent segment and discard the values in older segments.
Retrieval of data
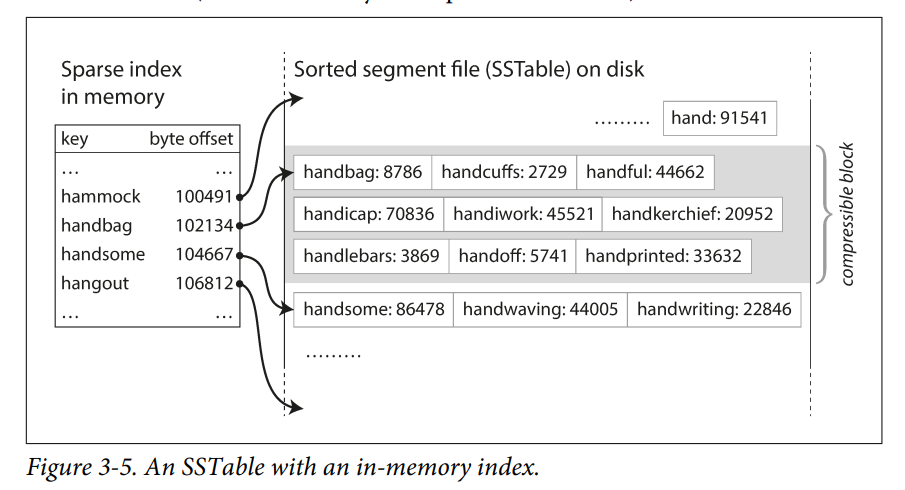
- In order to find a particular key in the file, you no longer need to keep an index of all the keys in memory.You still need an in-memory index to tell you the offsets for some of the keys, but it can be sparse: one key for every few kilobytes of segment file is sufficient, because a few kilobytes can be scanned very quickly.
- Since read requests need to scan over several key-value pairs in the requested range anyway, it is possible to group those records into a block and compress it before writing it to disk (indicated by the shaded area in Figure 3-5). Each entry of the sparse in-memory index then points at the start of a compressed block. Besides saving disk space, compression also reduces the I/O bandwidth use
References
- Ref:https://medium.com/the-developers-diary/sstables-and-lsm-trees-2e4b6c8be251
- Ref: Book: Design Data Intensive Application by Martin Kleppman